Corpora, concordances, search engines
A corpus (plural corpora) is a collection of textual data gathered by linguists (or other language researchers) for the purpose of study. Such a corpus is usually formed from text that belongs to a particular category or field of research (e.g., a corpus of Shakespeare’s plays), or formed from a representative sample of an otherwise impossible-to-capture language group or language practice (e.g., a corpus of American English). Digital corpora are often indexed in ways that support interfaces for easier research, such as the ability to search the corpus for particular words and to see those words in their original context (called a “concordance,” see below).
“Search engines” that you find in products like Facebook, Twitter and Google are, in fact, just interfaces to really big corpora. The corpus that backs Twitter Search is all of the tweets on Twitter; the corpus that backs Google Search is Google’s private copy of every (or nearly every) page on the web.
Corpora poetry
You can make your own corpus fairly easily, simply by collecting plain text that is of interest to you. For example, you could make a corpus of 19th century American poetry by visiting Project Gutenberg, searching for works in the category of “poetry” that have American authors and were written in the time period in question, then cut-and-pasting the content of each file into one big text file. (The exact technical details of how to do this vary from one tool to another, of course. But the idea is the same: gather a lot of text in one place.)
The simple act of making a decision about which texts should be brought together, and then gathering those texts, is itself a poetic act. Beyond this, common methods used in corpus analysis themselves often produce poetic output. The concordance, for example, shows the same word or phrase in all of the contexts it appears in; the resulting textual artifact has repetition and rhythm (from the appearances of the phrase) but also variation and surprise:
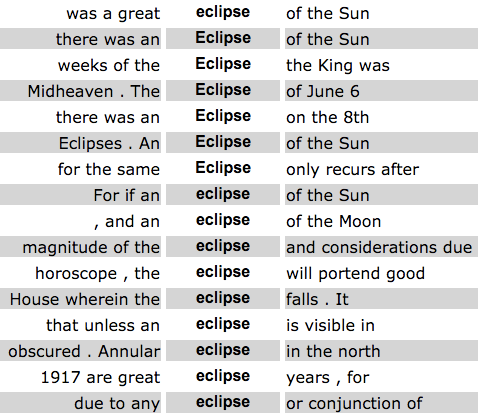
This is a concordance of the word “eclipse,” showing three words of context, in Astrology by Sepharial.
Corpus analysis with TaPORware
McMaster University makes available on the web a series of great text analysis tools called TAPoRware. Using these tools, you can create word lists, concordances and collocations from plain-text corpuses that you’ve collected.
The concordance
As described above, a concordance is a list of words that occur in a text along with the context the words occur in. Compiling a concordance for non-digital texts is a painstaking task, involving scouring a text for all occurences of a particular word and copying over the relevant context. Making a concordance of a digital text, however, is comparatively straightforward. Using TAPoRware’s Find Text - Concordance to make a concordance of a plain-text file is easy. Here are the steps:
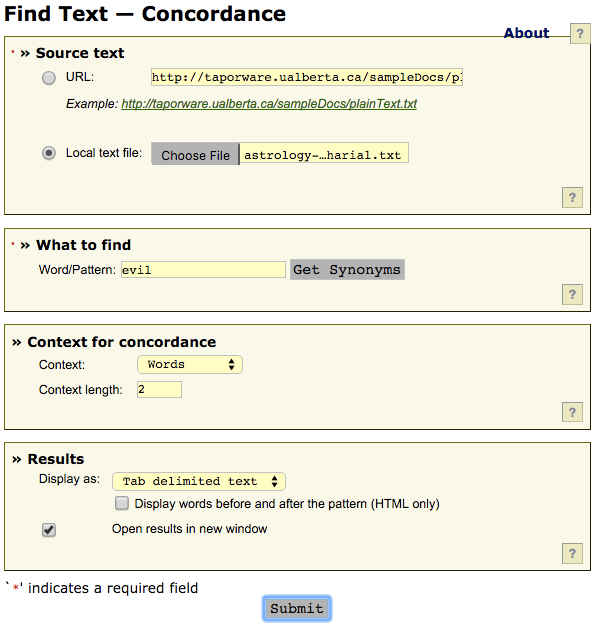
- Collect your corpus in a text file.
- Select “Local text file” in the “Source text” box and click “Choose File” to select your corpus file. (You can also use the URL option to work with a text already on the web)
- Enter the word or pattern (e.g., a series of words) that you want to find in the “Word/Pattern” box.
- The “Context for concordance” options control how much context will be shown. Adjust to your preferences!
- Select a way to display the results. We’ll use the tab-delimited output in a second to create output that looks more like a poem than a table.
Click submit, wait a few seconds, and then view the results.
Formatting concordance output
If you used the plain-text option, the text you see will look something like this:
48 entries found.
; the evil being the
good or evil . The
, and evil with malefic
are uniformly evil in effect
, are evil in their
when in evil aspect ;
be are evil or unfortunate
the other evil Mars .
conjunction or evil aspect .
not in evil aspect ,
good or evil . When
prevalence of evil aspects to
birth in evil aspect to
, in evil aspect to
by the evil aspects of
unafflicted by evil aspects or
aspects or evil positions .
or other evil aspect of
. IN EVIL ASPECT .
conjunction or evil aspect with
free from evil aspects ,
, in evil aspect to
those in evil aspect will
The formatting is weird because there are tab characters between each “field” (the fields being: context before your search term, the search term, and context after the search term). If you want, you can easily remove those tabs using TextMechanic’s Remove Extra Spaces tool. Paste in the text, click “Remove Extra Spaces,” and voila, a poem:
; the evil being the
good or evil . The
, and evil with malefic
are uniformly evil in effect
, are evil in their
when in evil aspect ;
be are evil or unfortunate
the other evil Mars .
conjunction or evil aspect .
not in evil aspect ,
good or evil . When
prevalence of evil aspects to
birth in evil aspect to
, in evil aspect to
by the evil aspects of
You can use this trick with text you cut-and-paste from many of the tools discussed in this tutorial.
Word lists
The TAPoRware site also has functionality for getting a unique list of words, along with their count, from any given text. Use the List Words tool. You’ll see something like this:
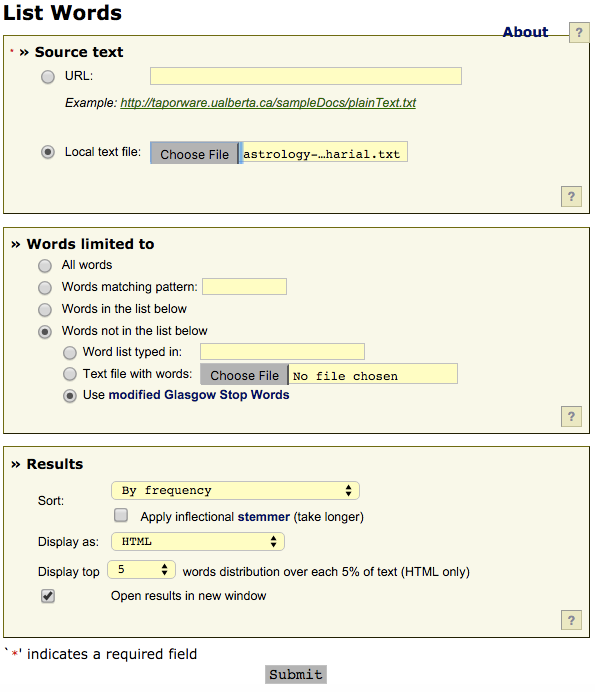
Keep the “Words limited to” and “Results” fields using their defaults for now. Click Submit and you’ll see something like this:
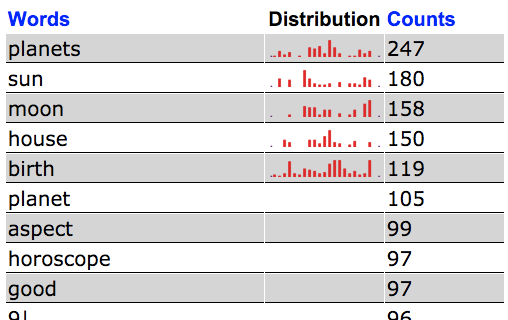
… or, a list of the most common words in the text. I think of this as a kind of poem based on the content of the document.
Stemmers and lemmas
If you select the “Apply inflectional stemmer” option in the concordance tool, the procedure will attempt to count all forms of a word as a single word in its counting operation. That means that “run”, “runs”, “running” and “ran” would all be counted as the same word.
Affixes and internal word changes that result in different forms of a word are called “inflections.” A word without any inflection is called a stem or a lemma; the process of removing inflections is called either “stemming” or “lemmatization.” (There are some technical differences between these two that we’ll gloss over here for the sake of brevity.)
Many text analysis tools provide stemming/lemmatization functionality, but
beware: stemming and lemmatization can be inaccurate or misleading. For
example, take the words operator and operation. The common meaning of
“operator” is someone who manages a telephone switchboard, or a mathematical
symbol like + or -; the common meaning of “operation” is a medical
procedure. Even though these meanings are very different, a stemmer or
lemmatizer might reduce both words to “operate,” thereby hindering your
ability to know whether the text was about switchboards or about open heart
surgery.
Stopwords
If you change the “Words not in the list below…” option to “All words,” you’ll notice that the output will usually look like this:
| Words | Counts |
|---|---|
| the | 3154 |
| of | 1539 |
| and | 1195 |
| in | 958 |
| to | 812 |
| is | 516 |
| a | 451 |
| be | 410 |
| or | 300 |
| it | 297 |
| are | 295 |
| will | 291 |
| that | 291 |
| which | 264 |
| planets | 247 |
… with words like “the” and “of” being at the top. It turns out that most English texts have a lot of the same words in common. As a consequence, these most common words tend to not be very valuable in distinguishing one text from another, and many text analysis tools have an option to automatically exclude such words from their analyses. These common words are called “stopwords.” TAPoRware gives you the option to exclude these words when creating a word list or a concordance.
The benefit of excluding stopwords is that you can more clearly see the differences between texts. The drawback is that stopwords, even though they seem “meaningless” on the surface, may actually be important in determining what a text means and excluding them may inadvertently bias your analysis.
There’s no one “accepted” list of stopwords that is appropriate for every project. If you must use stopwords, examine the list of stopwords carefully and make sure you understand what might be left out of your analysis by exclusing those words.
Corpora databases
The TAPoRware tools ask you to provide your own corpus. This allows for a great deal of flexibility, but there’s a limitation on how large your corpus can be. There are many websites on the Internet that provide access to large corpora that you can search and use to construct concordances. The benefit of these tools is that they allow you to work with a large amount of data, drawn from potentially interesting sources; the drawback is that you’re limited to using the tools they provide for searching and collating—you don’t have access to the “raw” data.
One such site is Skell, a smaller and more targeted (but free) version of Sketch Engine. Skell’s primary intention is to help people learning English by providing an easy interface to see words in context. (The sentences are drawn from a larger corpus of English news, scientific papers, Wikipedia articles, etc. Unfortunately, Skell doesn’t provide attribution for individual text snippets returned from the search.) But you can “misuse” the tool to run searches on a particular term and frame the results as poetry. Here’s an excerpt of a poem I wrote by searching for “a little bit later”:
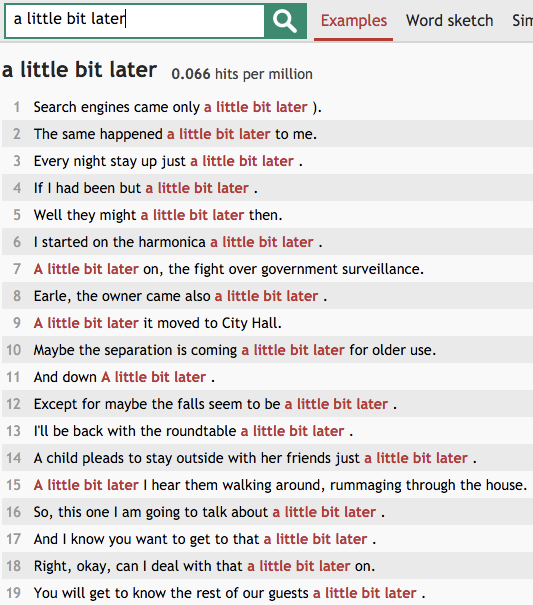
(Pasting this into TextMechanic to remove line numbers and extra spaces is left as an exercise for the reader.)
Advanced queries with the Leeds collection
One online corpora that I like to use is the Leeds collection of Internet corpora, which has a less complicated interface than some other tools and also provides an English corpus in which all the text is licensed as Creative Commons. To use the tool, select the radio button for corpus you’re interested in, type a search term into the search box and click “Submit.” You can adjust how many words or characters to show in the concordance using the form elements beneath the “Concordance” header. Here’s a search for “a few moments later” showing five words of context:

Queries with POS tags
The Leeds tool has a helpful feature that allows you to search not for a particular word but for words that belong to a particular part of speech (e.g., noun, adjective, adverb, etc.). To do this, you need to include a little bit of specifically formatted text in your search query, in place of where you would normally search for an exact word.
The full documentation is here, but I’ll explain the basics below. Say you started searching for the following phrase:
the black cat
… but then you realized that you wanted to search for cats described with any adjective, not just “black.” To do this, you need to replace the word “black” with a special tag that looks like this:
the [pos="JJ"] cat
That “JJ” is weird, but try the search out first to make sure it works. The output might look like this (using two words of context):

The general syntax for including a word belonging to a particular part of speech in your search is
[pos="..."]
… where ... should be replaced with a “tag.” Tags are short codes for
different parts of speech.
You can access a list of supported tags for each corpus in the Leeds tool by clicking the “tags” links in the search interface. Some of the most common and helpful tags are listed below:
| Tag | Meaning |
|---|---|
| NN | singular noun |
| NNS | plural noun |
| JJ | adjective |
| VVD | past-tense verb |
| VVG | present participle or gerund of verb |
| RB | adverb |
| IN | preposition |
The tags used by the Leeds tool are a variation on the tags used by many other
corpus analysis tools, originally popularized by the Penn Treebank project.
Those tags are listed
here.
(I can’t explain why JJ is the tag for “adjective.” I wish I could. But
that’s a decision that someone made once and now we all have to live with it.)
You can use more than one tag in your query. For example, this search:
[pos="RB"] loved the [pos="NN"]
… will create a corpus poem that details what people loved and how they loved it:

Formatting text from tables
Unfortunately, the Leeds tool doesn’t offer the option of exporting in plain text, so you’ll need to do some serious massaging to the text in order to make it look like a poem. The easiest way I know of to do this without downloading any software is to use Google Sheets, a spreadsheet program that is a part of Google Drive.
If you select the entire table of output from the Leeds tool and paste it into a fresh Google Sheets document, you’ll get something like this:
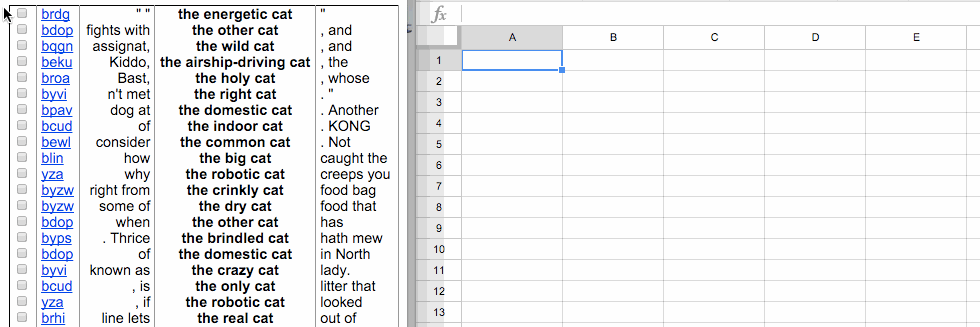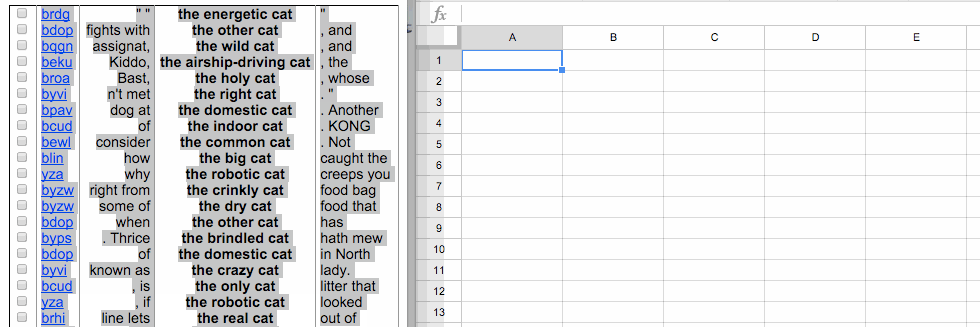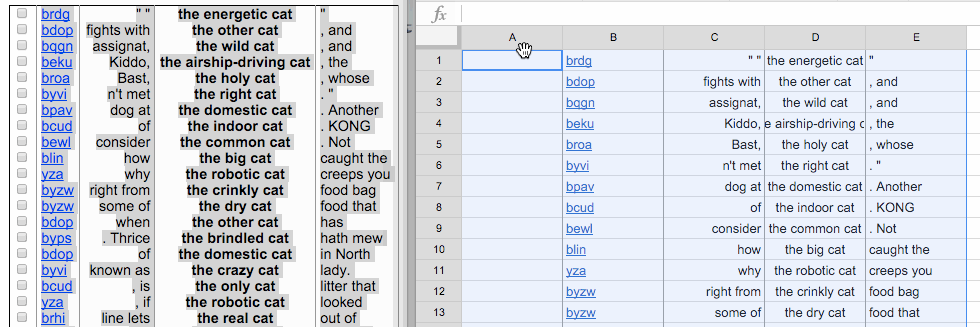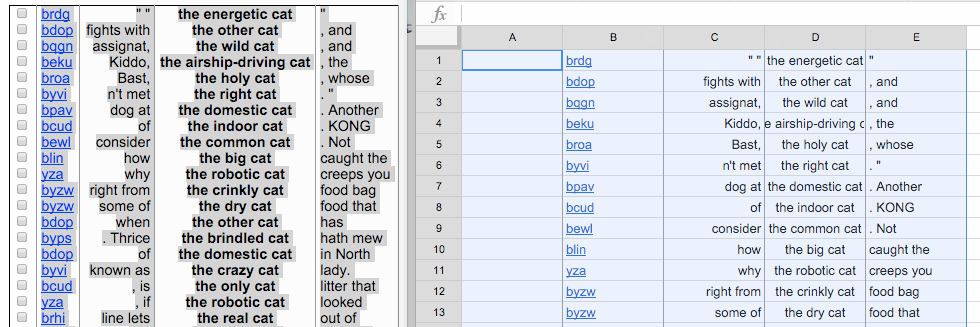
Now you can delete the columns of the table that you don’t want—in this case, the leftmost empty column and the column with the codes that correspond to the source of the text:
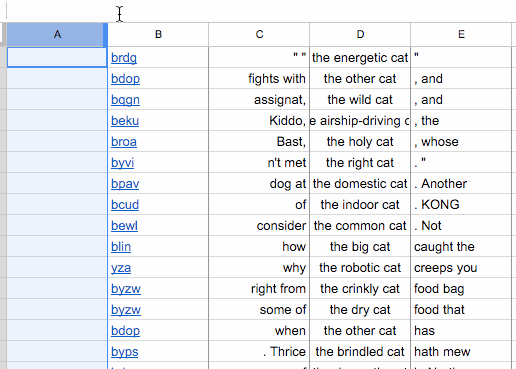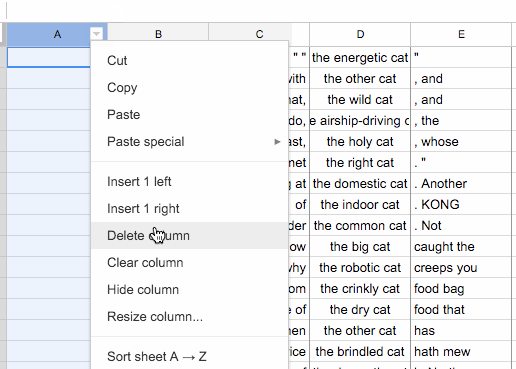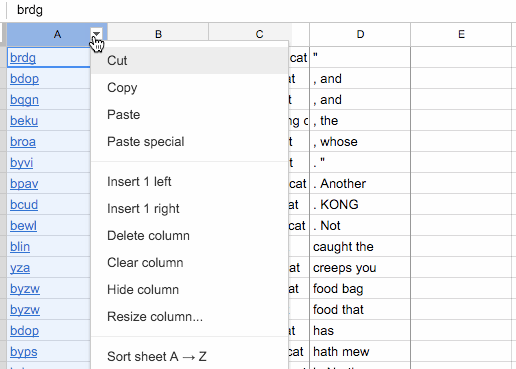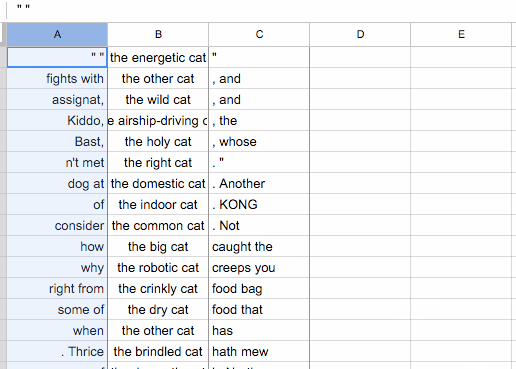
At this point, you can paste the text into a plain text editor and see something like this:
" " the energetic cat "
fights with the other cat , and
assignat, the wild cat , and
Kiddo, the airship-driving cat , the
Bast, the holy cat , whose
n't met the right cat . "
dog at the domestic cat . Another
of the indoor cat . KONG
consider the common cat . Not
how the big cat caught the
why the robotic cat creeps you
right from the crinkly cat food bag
some of the dry cat food that
when the other cat has
. Thrice the brindled cat hath mew
of the domestic cat in North
known as the crazy cat lady.
, is the only cat litter that
, if the robotic cat looked
Using the same tricks with TextMechanic that we discussed above, you can easily remove the extra spaces from this and even clean up some of the punctuation, using the search and replace tool. (Or you can do all of this by hand if you want.) The finished poem might look something like this:
the energetic cat
fights with the other cat and
assignat the wild cat and
Kiddo the airship-driving cat the
Bast the holy cat whose
n't met the right cat.
dog at the domestic cat. Another
of the indoor cat. KONG
consider the common cat. Not
how the big cat caught the
why the robotic cat creeps you
right from the crinkly cat food bag
some of the dry cat food that
when the other cat has
Thrice the brindled cat hath mew
of the domestic cat in North
known as the crazy cat lady.
is the only cat litter that
if the robotic cat looked
Autocomplete poetry
Web search engines like Google Search are, at their core, just tools that generate concordances from corpora. In the case of Google Search, the corpus in question is all of the web pages on the Internet (a large corpus indeed). Google also maintains a corpus of all of the search terms that their users use in the search engine, which is what the web interface draws from when displaying suggested searches:
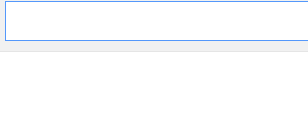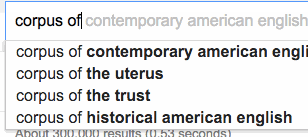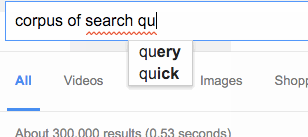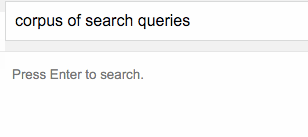
Supplying suggestions for what you should type in real-time is often called “autocompletion.” It’s not all that different from the corpus search tools that we examined above—the main difference being that the autocomplete interface is interactive, which makes the tool feels like you’re performing and playing, instead of just issuing a search query.
Google Poetics is a site that accepts submissions of and publishes poetry made with Google Autocomplete (more about the site here). Unfortunately, there’s no easy way to capture the result of your play with the autocompletion tool, other than taking a screenshot and then transcribing from the screenshot.
Other websites have autocomplete tools as well. Most search engines do (like Yahoo and Bing) and Wikipedia as well. (In the case of Wikipedia, as of this writing, the autocomplete isn’t showing you results from a corpus of searches but instead results from a corpus of article titles.)
I personally love working with autocompletion tools, so I made one specifically for readers of this tutorial: Gutenberg Poetry Autocomplete. Gutenberg Poetry Autocomplete has as its corpus all of the lines of poetry in any Project Gutenberg book. As you type, it displays the lines of poetry that begin with what you’ve typed. You can add individual lines to the “output” area by clicking on them, or click on “Add All” to add all of the lines, allowing you to build up a poem bit by bit.
Next steps
Other interesting corpora interfaces that you can access online that allow you to create concordances:
- Mark Davies’ corpus.byu.edu, including Corpus of Contemporary American English
- Michigan Corpus of Academic Spoken English
- Phrases In English uses data from the BNC. The Find concordances feature lets you search for keywords and context in the corpus.
- A more complete list of online corpora from UNC; another list from the University of Washington.
AntConc is a popular downloadable tool for doing corpus analysis. Heather Froehlich’s AntConc tutorial is a great introduction to AntConc that doesn’t assume a lot of technical knowledge.
Further reading: